





The Data Plane Development Kit (DPDK) has significantly transformed the world of high-performance networking, allowing network engineers to bypass the operating system kernel and achieve ultra-low latency and high-throughput packet processing.
One of the most powerful features of DPDK is pipeline mode, which divides packet processing into multiple stages, optimizing the distribution of workloads across CPU cores.
In this guide, we’ll dive into how to set up and use DPDK in pipeline mode, from configuring hugepages to implementing core-to-pipeline mapping and exploring real-world DPDK application examples.
Whether you’re designing advanced packet forwarding applications for a data center or crafting complex routing and classification pipelines, DPDK pipeline mode is a game-changer for maximizing packet handling efficiency.
This article will provide a step-by-step approach to setting up DPDK and offer insights into best practices for optimizing performance in pipeline mode.
How to Run DPDK in Pipeline Mode?
Running DPDK in pipeline mode requires several key configurations. First, you need to install the Data Plane Development Kit on your system and configure your environment.
This includes using tools like Meson and Ninja build tools to compile DPDK and binding your Intel NICs to DPDK via dpdk-devbind.py. Once your system is set up, you can begin allocating hugepages—large memory pages that ensure DPDK has sufficient memory for real-time packet processing.
Next, you’ll need to configure your system for core isolation using the core mask (-c) and port mask (-p) options to dedicate specific CPU cores to DPDK tasks. The goal is to isolate DPDK packet processing from other operating system tasks, ensuring maximum scalability in packet processing.
The l3fwd-pipeline sample app is a great starting point for testing and understanding how DPDK pipeline mode operates, as it demonstrates a modular pipeline for packet forwarding that can be tailored for various use cases.

Why Use Pipeline Mode for Packet Processing?
Pipeline mode in DPDK offers numerous advantages for optimizing network performance. By breaking down packet processing into multiple stages, each handled by a dedicated CPU core, you can achieve better scalability and efficiency.
This modular approach helps to balance workloads, improving packet handling efficiency and reducing bottlenecks. For example, one core could handle classification, while another handles filtering and forwarding, ensuring that each stage runs independently and at maximum speed.
Moreover, pipeline mode allows for fine-tuned core-to-pipeline mapping, enabling you to allocate cores based on workload priority. DPDK’s modular pipelines are especially beneficial for environments where real-time debugging tools are needed to monitor performance continuously.
This structure not only accelerates packet processing but also reduces latency, making it ideal for high-performance networking applications like telecom networks, security appliances, and high-frequency trading platforms.
Read Also: How to Increase Girth Size Permanently
System Prerequisites and Environment Setup
To successfully implement DPDK pipeline mode, you must first ensure that your system meets certain prerequisites. Start by installing a Linux-based operating system as DPDK relies on the Linux kernel-bypass mechanism.
Additionally, Intel NICs are required for DPDK to work efficiently with high-performance networking capabilities. These NICs are optimized for DPDK’s low-latency operations, allowing your system to handle large data volumes at extremely fast speeds.
Additionally, you must configure hugepages on your system to allow DPDK to use larger memory blocks for data processing. This is critical for high-speed packet processing, as the operating system’s standard memory pages are too small for DPDK to function optimally.
By allocating hugepages, you ensure that the system can handle large data flows with minimal overhead, thus accelerating packet processing and improving network performance optimization.
Installing and Building DPDK
The process of installing and building DPDK involves several straightforward steps. Begin by downloading the DPDK source code from the official repository, then use Meson and Ninja build tools to compile the code.
These tools are known for their speed and efficiency in managing builds, making the process much faster than traditional make-based systems. Once the code is compiled, you’ll need to install DPDK and configure the system for NIC binding and hugepages.
After installation, it’s essential to verify the integrity of your DPDK setup. You can use dpdk-procinfo, a DPDK debugging tool, to check whether DPDK is functioning correctly and to gather real-time metrics on performance. This ensures that your DPDK pipeline mode setup is complete and ready for use.
With DPDK installed and configured, you’re now prepared to dive into more advanced pipeline configurations, such as creating custom pipeline files and running sample applications.
Configuring Hugepages and NIC Binding
A critical step in the DPDK pipeline mode setup is configuring hugepages and NIC binding. Hugepages are essential for DPDK as they allow memory to be allocated in larger blocks, which improves packet processing performance.
By configuring hugepages on your system, you avoid memory fragmentation and overhead, ensuring that DPDK can operate efficiently. You can allocate hugepages by modifying the system’s boot parameters or using the dpdk-devbind.py script to bind Intel NICs to DPDK, ensuring they are used for packet forwarding tasks.
NIC binding ensures that your Intel NICs are dedicated to DPDK, bypassing the kernel and allowing high-performance networking. This binding enables DPDK to have direct access to the network interfaces, significantly improving packet throughput.
Once NICs are bound and hugepages are configured, you’re ready to run DPDK applications that leverage the full potential of your system’s hardware.
Exploring the l3fwd-pipeline Sample Application
One of the easiest ways to get started with DPDK in pipeline mode is by exploring the l3fwd-pipeline sample app. This application demonstrates the use of modular pipelines for packet forwarding and provides a foundation for more complex network applications.
It splits packet processing into several stages, with each stage running on different CPU cores, allowing you to observe how core-to-pipeline mapping works in action.
The l3fwd-pipeline sample app also showcases the concept of routing and classification pipelines, where packets are categorized and forwarded according to specific rules. This modular approach can be extended to create customized DPDK application examples tailored to various networking tasks.
By experimenting with this sample application, you can better understand how to build scalable and efficient packet processing solutions using DPDK pipeline mode.
Creating a Custom Pipeline Configuration File
To create a custom pipeline configuration file, you need to define how the stages of packet processing will be distributed across different cores. In DPDK, this is done by specifying the number of stages in the pipeline and mapping them to available CPU cores using core mask (-c) and port mask (-p).
This configuration allows for maximum resource utilization and efficient packet processing frameworks. Custom pipeline files also allow you to define custom forwarding logic, such as packet filtering or load balancing, and specify how packets should be routed across different network interfaces.
By customizing your pipeline configuration, you can create highly optimized packet forwarding applications that meet the unique requirements of your network environment.
Running DPDK in Pipeline Mode: Command Breakdown
Running DPDK in pipeline mode requires executing specific commands to launch your DPDK application. The core mask (-c) and port mask (-p) are essential for specifying which CPU cores and network ports should be used for packet processing.
These options allow you to allocate resources efficiently, ensuring that DPDK can perform at its best. Additionally, you can specify various other parameters depending on your use case, such as the number of queue pairs, memory channels, and the size of the packet buffers.
By understanding these command-line options, you can fine-tune your DPDK pipeline mode setup for maximum performance, tailoring it to suit your specific network configuration.
Debugging and Monitoring Your Pipeline
Once your DPDK pipeline mode is running, it’s essential to monitor its performance to ensure optimal operation. DPDK debugging tools, like dpdk-procinfo, provide real-time insights into memory usage, core utilization, and packet throughput.
These tools help you identify bottlenecks and inefficiencies in your pipeline, allowing you to make adjustments for improved performance. Additionally, you can use real-time debugging tools to monitor packet flow through the pipeline, checking for packet loss or delays.
By constantly monitoring and tweaking your pipeline configuration, you can ensure that your high-performance networking solution delivers the best possible results.
Optimizing Performance in Pipeline Mode
To get the most out of DPDK pipeline mode, optimizing the performance of your pipeline is crucial. One key factor in optimization is ensuring that CPU cores are properly isolated and allocated to specific stages in the pipeline.
This prevents interference from the operating system and allows DPDK to run at maximum efficiency. Another performance optimization strategy is to reduce the number of memory copies and buffer allocations during packet processing.
By minimizing these operations, you reduce overhead and improve packet throughput. Finally, consider adjusting the size of hugepages and the core-to-pipeline mapping to match the unique demands of your network environment.
Real-World Applications of DPDK Pipeline Mode
DPDK pipeline mode is widely used in real-world scenarios where high-performance networking and low-latency packet processing are essential. One common use case is in telecommunications for packet forwarding and traffic classification in 5G networks.
By using DPDK pipeline mode, telecom providers can efficiently handle high volumes of data, ensuring that packets are processed quickly and routed without delay. This is crucial for maintaining the quality of service (QoS) in environments that demand real-time data processing, such as video streaming and online gaming.
Another real-world application is in network security appliances, where DPDK pipeline mode can be used to implement firewalls and intrusion detection systems (IDS). These security systems require high throughput and low latency to inspect and filter incoming traffic for potential threats.
By breaking down the packet processing into multiple pipeline stages, DPDK enables security devices to analyze and forward packets at much higher speeds compared to traditional software-based solutions, making them more effective at mitigating attacks.
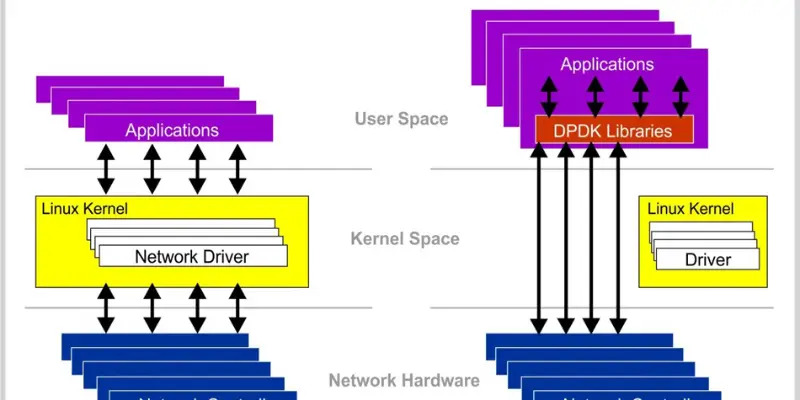
Common Challenges and How to Troubleshoot Them
While DPDK pipeline mode offers great benefits, it also comes with some challenges. One of the most common issues is improper configuration of hugepages, which can lead to memory fragmentation and DPDK application crashes.
To troubleshoot this issue, you can use tools like dpdk-procinfo to check whether hugepages are correctly allocated and monitor memory usage during runtime. Ensuring that hugepages are appropriately configured during the initial system setup can avoid this problem.
Another challenge in pipeline mode is achieving load balancing across CPU cores. If one core is overloaded while others are underutilized, it can create a performance bottleneck.
You can address this by optimizing the core-to-pipeline mapping and adjusting the number of cores assigned to each stage of the pipeline. Tools like perf and top can be used to monitor CPU usage and help identify bottlenecks in the pipeline.
Best Practices for Designing Modular Pipelines
When designing modular pipelines in DPDK, it’s essential to maintain a scalable architecture that can adapt to changing workloads. A good practice is to break down the pipeline into small, manageable stages, each responsible for a specific function, such as packet classification, filtering, or forwarding.
By isolating tasks into individual stages, you can ensure that each stage runs efficiently without causing a performance bottleneck. Additionally, using dedicated cores for each stage prevents interference between pipeline stages and maximizes throughput. Another important best practice is core isolation.
By allocating specific CPU cores to each stage of the pipeline, you prevent the operating system from interrupting DPDK’s processing. This ensures that all cores are dedicated to packet forwarding, resulting in lower latency and improved performance.
You should also test your modular pipeline under various workloads to ensure it can handle peak traffic volumes without degradation in speed.
Future Trends in DPDK and Pipeline Processing
The future of DPDK and pipeline processing is closely tied to the continued evolution of networking technologies. As the demand for 5G networks and edge computing increases, DPDK will play an integral role in delivering the high-speed packet processing required for these next-generation systems.
The ability to scale pipeline stages dynamically and distribute workloads across multi-core systems will be essential for meeting the performance demands of these emerging technologies. Furthermore, machine learning (ML) and artificial intelligence (AI) are expected to play a larger role in packet processing pipelines.
Future DPDK applications may incorporate AI-driven techniques for traffic classification, anomaly detection, and dynamic load balancing.
This could lead to more intelligent networks that automatically adjust pipeline configurations based on traffic patterns, further improving the performance and efficiency of DPDK pipeline mode.
Read Also: Harry Potter Illustrated Book 6
Final Thoughts
DPDK pipeline mode offers a powerful solution for high-performance networking applications, enabling low-latency packet processing and high throughput.
Whether used in telecommunications, network security, or data centers, DPDK pipeline mode can dramatically improve the performance of network applications by dividing packet processing into manageable stages and efficiently utilizing CPU resources.
By following best practices such as core isolation and optimizing core-to-pipeline mapping, you can unlock the full potential of DPDK for your networking needs.
As networking demands continue to grow, DPDK pipeline mode will remain a key player in shaping the future of high-speed packet processing.
By staying informed about new advancements and incorporating emerging technologies such as AI and ML, you can ensure that your DPDK pipeline mode applications remain at the cutting edge of performance and scalability.
FAQs
What is DPDK pipeline mode?
DPDK pipeline mode is a technique used to divide packet processing into multiple stages, with each stage running on a separate CPU core. This approach enhances scalability and packet processing efficiency, allowing for high-speed networking and low-latency operations.
How do I install DPDK for pipeline mode?
To install DPDK, you need to first compile the source code using Meson and Ninja build tools. After installation, bind your NICs to DPDK using dpdk-devbind.py, configure hugepages for memory allocation, and set up core masks for core isolation.
What are the main challenges of using DPDK pipeline mode?
Common challenges include configuring hugepages properly, ensuring core isolation for packet forwarding, and achieving efficient load balancing across CPU cores. Tools like dpdk-procinfo and perf can help troubleshoot these issues.
Can I customize my DPDK pipeline configuration?
Yes, DPDK allows you to customize your pipeline configuration by defining the number of stages and mapping them to specific CPU cores. This flexibility enables you to tailor the pipeline to suit your networking needs.
What are the best practices for optimizing DPDK pipeline mode?
Best practices include breaking down the pipeline into small, modular stages, isolating cores for each stage, optimizing core-to-pipeline mapping, and testing the pipeline under peak traffic conditions to ensure it can handle high loads without degradation.
How will machine learning impact DPDK pipeline processing?
Machine learning is expected to enhance DPDK pipeline mode by enabling intelligent traffic classification, dynamic load balancing, and automated performance adjustments based on real-time traffic patterns. This will help networks become more adaptive and efficient.



